Plausibly reconstructing noisy or incomplete images, and some thoughts about the relation between data, models, and predictions
27 August 2004
Paul Harrison (PhD student, Monash University)
pfh at logarithmic dot net
Consistency
The consistency (texture) of a thing is what is the same throughout it:
- The kinds of parts that make up a thing
- The ways those parts tend to be connected
Everything has a consistency:
- Porridge
- A brick
- A symphony
- A painting
- The actions a person takes
- The motion of sub-atomic particles
If we have partial knowledge of a thing, knowing its consistency allows us to guess at where missing parts should go. We can produce a plausible reconstruction.
Jigsaw puzzles
Plausible reconstruction is like solving a partially completed jigsaw puzzle. You build on what you know a layer at a time (though sometimes you may have to backtrack).
Emergence of complex forms from simple rules of connection is possible. Consistency and form are two ways of looking at the same thing.
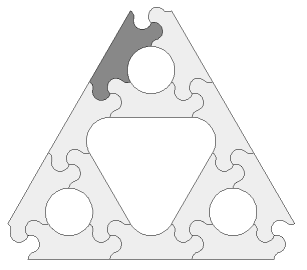
Jigsaw pieces of the correct shape (eg Wang tiles) can perform any computation. Plausible reconstruction is not an easy problem!
People are very, very good at plausible reconstruction
If an object is partially occluded, we have no difficulty imagining the occluded area. Indeed, this is automatic and somewhat involuntrary.
(people who were bad at plausible reconstruction were most likely all eaten by partially occluded lions and tigers)

Working with images lets us compare algorithms we create to the way our own brains work.
Plausible reconstruction of incomplete data
A missing area may be reconstructed using best-fit texture synthesis (Efros and Leung, 1999).
Best-fit treats images like jigsaw puzzles. We choose a pixel at a time, finding a pixel in the input with a neighbourhood of surrounding pixels that fits well with pixels already in the output.
The choice is slightly random. We are sampling not optimizing.

Best-fit synthesis can only use pieces it has seen before. Better to extrapolate, from the pieces we have available, the full set of pieces. For this, we will need a texture model.
Plausible reconstruction of imprecise or incomplete data
Problem:
Given bounds on the value of each pixel in an image, produce a plausible reconstruction of that image.
Applications:
- Filling in of missing areas
- Noise removal
- GIF, JPEG restoration
- Correction of over-exposure
A Least Squares texture model
Raster-scan of image.
Predict each pixel from "previous" pixels, eg:
Prediction(x,y) = weight_0 * image(x-1,y) +
weight_1 * image(x-1,y-1) +
weight_2 * image(x,y-1) +
weight_3 * image(x+1,y-1) +
weight_4 * image(x-1,y) * image(x-1,y) +
weight_5 * image(x-1,y) * image(x-1,y-1)
... etc ...
Prediction error:
2
sum (image(y,x)-prediction(y,x))
y,x
Choose both weight and image to minimize this sum.
The model most consistent with the image, and the image most consistent with the model.
Palettization
Over-exposure


This method finds the Maximum Likelyhood image, it does not sample. Sometimes the Maximum Likelyhood image is not representative of the field of all possibilities.
Blue sky 1: Covering all possibilities
Need not choose a single texture model. Multiple, possibly contradictory models could explain the facts we have. Models constructed from unbiassed statistics, MML, etc, are approximations.
Monte Carlo characterization:
- Sample model-image pairs
- Perform statistics on this sample
Perhaps using Metropolis-Hastings sampling: random walk over all possible models.
May also be useful for other types of data.
Blue sky 2: Self-modelling
Track multiple variables over time, construct plausible futures.
Example: health modelling. What if your computer says that you are stressed and are about to collapse? You take a day off. But then the computer would have been wrong.
If the computer is part of the system it is trying to predict, there might be no single correct prediction it could make.
Similar problem occurs with games such as Chess or financial markets, or (blue, blue sky) an A.I. modelling its own behaviour.
Choosing a single model can sometimes be misleading. Sampling model-data pairs does not have this problem, and might be feasible to implement.